Happy Little Words
Posted on November 20th, 2015.
In late October the video game streaming site Twitch.tv launched "Twitch Creative", essentially giving people permission to stream non-video game related creative content on the site. To celebrate the launch they streamed all 403 episodes of The Joy of Painting with Bob Ross in a giant marathon.
The Bob Ross channel has its own chat room, and it quickly became packed with folks watching Bob paint. The chat spawned its own memes and conventions within days, mostly taking gamer slang (e.g. "gg" for "good game") and applying it to the show (people spam "gg" in the chat whenever Bob finishes a painting).
Sadly that marathon has ended, but they've kept the dream alive by having "Bob Ross Night" on Mondays. Every Monday they're going to stream a season of the show twice (once at a Europe-friendly time and again for American folks). Last Monday I scraped the Twitch chat during the marathon(s) of Season 2 and decided to have some fun poking around at the data.
Scraping
Scraping the chat was pretty easy. Twitch has an IRC gateway for chats, so
I just ran an IRC client (weechat) on a VPS and had it log the channel like
any other. Once the marathon finished I just scp'ed down the 8mb log and
started working with it.
First I trimmed both ends to only leave messages from about an hour and a half before and after the marathons started and ended. So the data I'm going to work with runs from 2015-11-16 14:30 to 2015-11-17 07:30 (all times are in UTC), or 17 hours.
Then I cleaned it up to remove some of the cruft (status messages from the client and such) and lowercase everything:
cat data/raw | grep -E '^[^\t]+\t <' | gsed -e 's/./\L\0/g' > data/log
Then I made an ugly little Python script to massage the data into something a bit easier to work with later:
import datetime, sys, time
def datetime_to_epoch(dt):
return int(time.mktime(dt.timetuple()))
for line in sys.stdin:
timestamp, nick, msg = (s.strip() for s in line.split('\t', 2))
timestamp = datetime_to_epoch(
datetime.datetime.strptime(timestamp, '%Y-%m-%d %H:%M:%S'))
# strip off <>'s
nick = nick[1:-1]
print(timestamp, nick, msg)This results in a file with one message per line, in the format:
timestamp nick message goes here...
On a side note: I tried out Mosh for persisting a connection to the server (instead of using tmux or screen to persist a session) and it worked pretty well. I might start using it more often.
Volume
Now that we've got a nice clean corpus, let's start playing with it!
The obvious first question: how many messages did people send in total?
><((°> cat data/messages | wc -l
165368
That's almost 10,000 messages per hour! And since there were periods of almost no activity before, between, and after the two marathons it means the rate during them was well over that!
Who talked the most?
><((°> cat data/messages | cuts -f 2 | sort | uniq -c | sort -nr | head -5
269 fuscia13
259 almightypainter
239 sabrinamywaifu
235 roudydogg1
201 ionone
Some talkative folks (though honestly I expected a bit higher numbers here).
cuts is "cut on spaces" — a little function I use so I don't have
to type -d ' ' all the time.
N-grams
The chat has spawned a bunch of its own memes and jargon. I made another ugly Python script to split up messages into n-grams so we can analyze them more easily:
import sys
import nltk
def window(coll, size):
'''Generate a "sliding window" of tuples of size l over coll.
coll must be sliceable and have a fixed len.
'''
coll_len = len(coll)
for i in range(coll_len):
if i + size > coll_len:
break
else:
yield tuple(coll[i:i+size])
for line in sys.stdin:
timestamp, nick, msg = line.split(' ', 2)
n = int(sys.argv[1])
for ngram in set(window(nltk.word_tokenize(msg), n)):
print(timestamp, nick, '__'.join(ngram))This lets us easily split a message into unigrams:
><((°> echo "1447680000 sjl beat the devil out of it" | python src/split.py 1
1447680000 sjl it
1447680000 sjl the
1447680000 sjl beat
1447680000 sjl of
1447680000 sjl out
1447680000 sjl devil
The order of n-grams within a message isn't preserved because the splitting
script uses a set to remove duplicate n-grams. I wanted to remove dupes
because it turns out people frequently copy and paste the same word many times
in a single message and I didn't want that to throw off the numbers.
Bigrams are just as easy — just change the parameter to split.py:
><((°> echo "1447680000 sjl beat the devil out of it" | python src/split.py 2
1447680000 sjl of__it
1447680000 sjl the__devil
1447680000 sjl beat__the
1447680000 sjl devil__out
1447680000 sjl out__of
N-grams are joined with double underscores to make them easier to plot later.
So what are the most frequent unigrams?
><((°> cat data/words | cuts -f3 | sort | uniq -c | sort -nr | head -15
19523 bob
14367 ruined
11961 kappaross
11331 !
10989 gg
7666 is
6592 the
6305 ?
6090 i
5376 biblethump
5240 devil
5122 saved
5075 rip
4813 it
4727 a
Some of these are expected, like "Bob" and stopwords like "is" and "the".
The chat loves to spam "RUINED" whenever Bob makes a drastic change to the painting that looks awful at first, and then spam "SAVED" once he applies a bit more paint and it looks beautiful. This happens frequently with mountains.
"KappaRoss" and "BibleThump" are Twitch emotes that produce small images in the chat.
When Bob cleans his brush he beats it against the leg of the easel to remove the paint thinner, and he often smiles and says "just beat the devil out of it". It didn't take long before chat started spamming "RIP DEVIL" every time he cleans the brush.
How about the most frequent bigrams and trigrams?
><((°> cat data/bigrams | cuts -f3 | sort | uniq -c | sort -nr | head -15
3731 rip__devil
3153 !__!
2660 bob__ross
2490 hi__bob
1844 <__3
1838 kappaross__kappaross
1533 bob__is
1409 bob__!
1389 god__bless
1324 happy__little
1181 van__dyke
1093 gg__wp
1024 is__back
908 i__believe
895 ?__?
><((°> cat data/trigrams | cuts -f3 | sort | uniq -c | sort -nr | head -15
2130 !__!__!
1368 kappaross__kappaross__kappaross
678 van__dyke__brown
617 bob__is__back
548 ?__?__?
503 biblethump__biblethump__biblethump
401 bob__ross__is
377 hi__bob__!
376 beat__the__devil
361 bob__!__!
331 bob__<__3
324 <__3__<
324 3__<__3
303 i__love__you
302 son__of__a
Looks like lots of love for Bob and no sympathy for the devil. It also seems like Van Dyke Brown is Twitch chat's favorite color by a landslide.
Note that the exact n-grams depend on the tokenization method. I used NLTK's
word_tokenize because it was easy and worked pretty well.
wordpunct_tokenize also works, but it splits up basic punctuation a bit too
much for my liking (e.g. it turns bob's into three tokens bob, ', and s,
where word_tokenize produces just bob and 's).
Graphing
Pure numbers are interesting, but can be misleading. Let's make some graphs to get a sense of what the data feels like. I'm using gnuplot to make the graphs.
What does the overall volume look like? We'll use minute-wide buckets in the x axis to make the graph a bit easier to read.
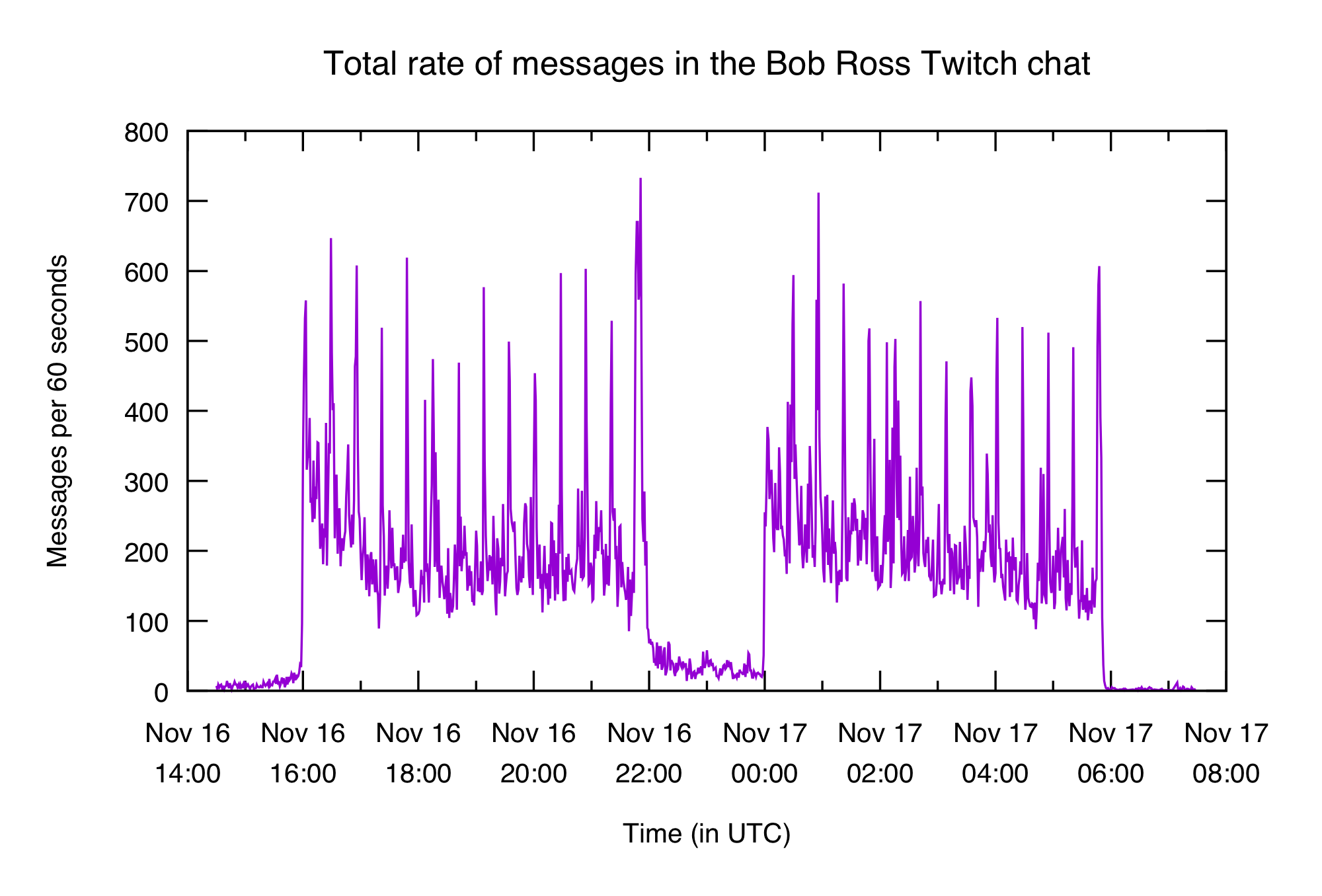
Can you tell where the two marathons start and end?
Let's try to identify where episodes start and finish. Chat usually spams "hi bob" when an episode starts and "gg" when it finishes, so let's plot those. We'll use 30-second x buckets here because a minute isn't a fine enough resolution for the events we're looking for. To make it easier to read we'll just look at the first half of the first marathon.
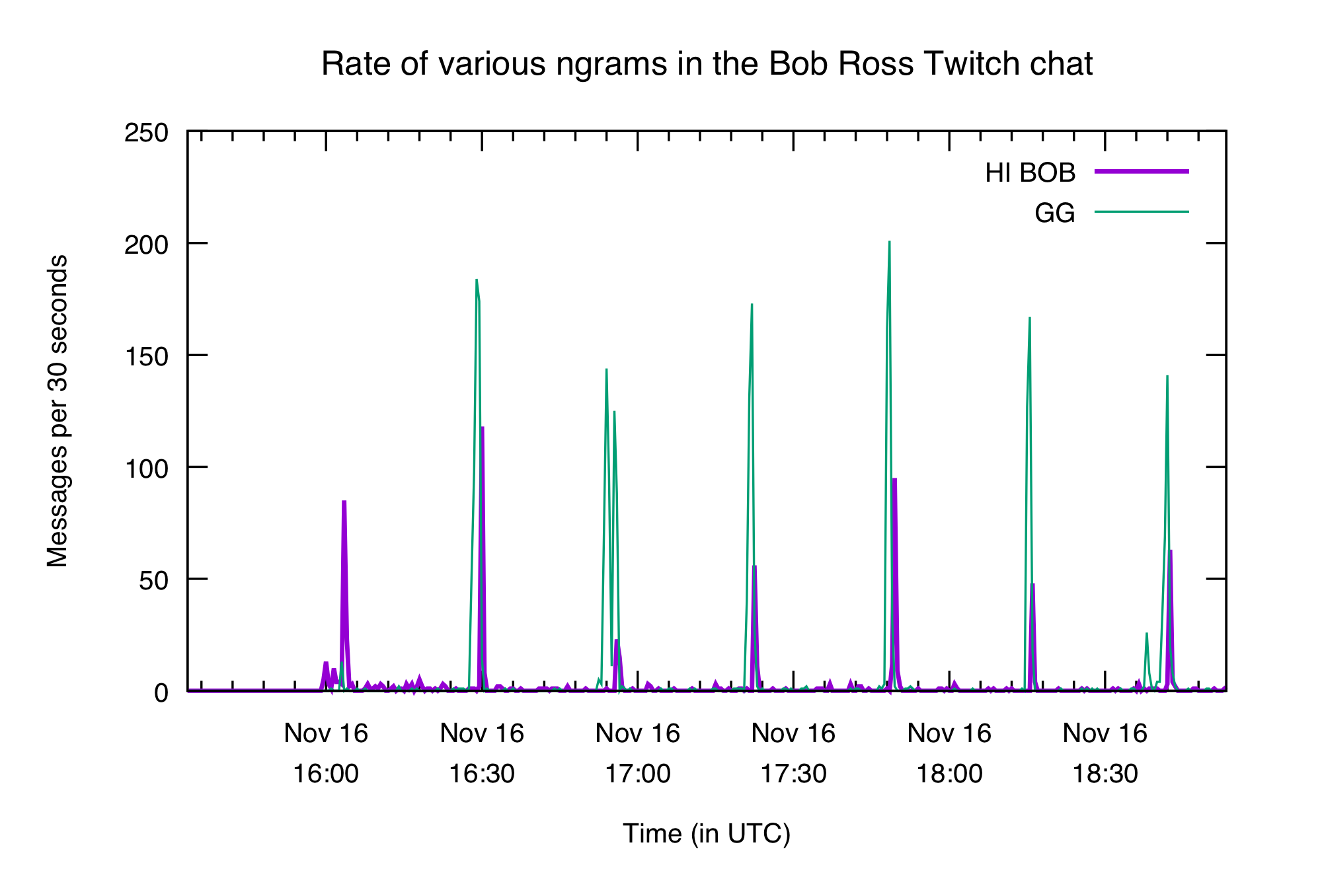
This works pretty well! The graph starts with a big spike of "hi bob", then as each episode finishes we see a (huge) spike of "gg", followed immediately by a round of "hi bob" as the next episode starts.
Can we find all the times Bob cleaned his brush?
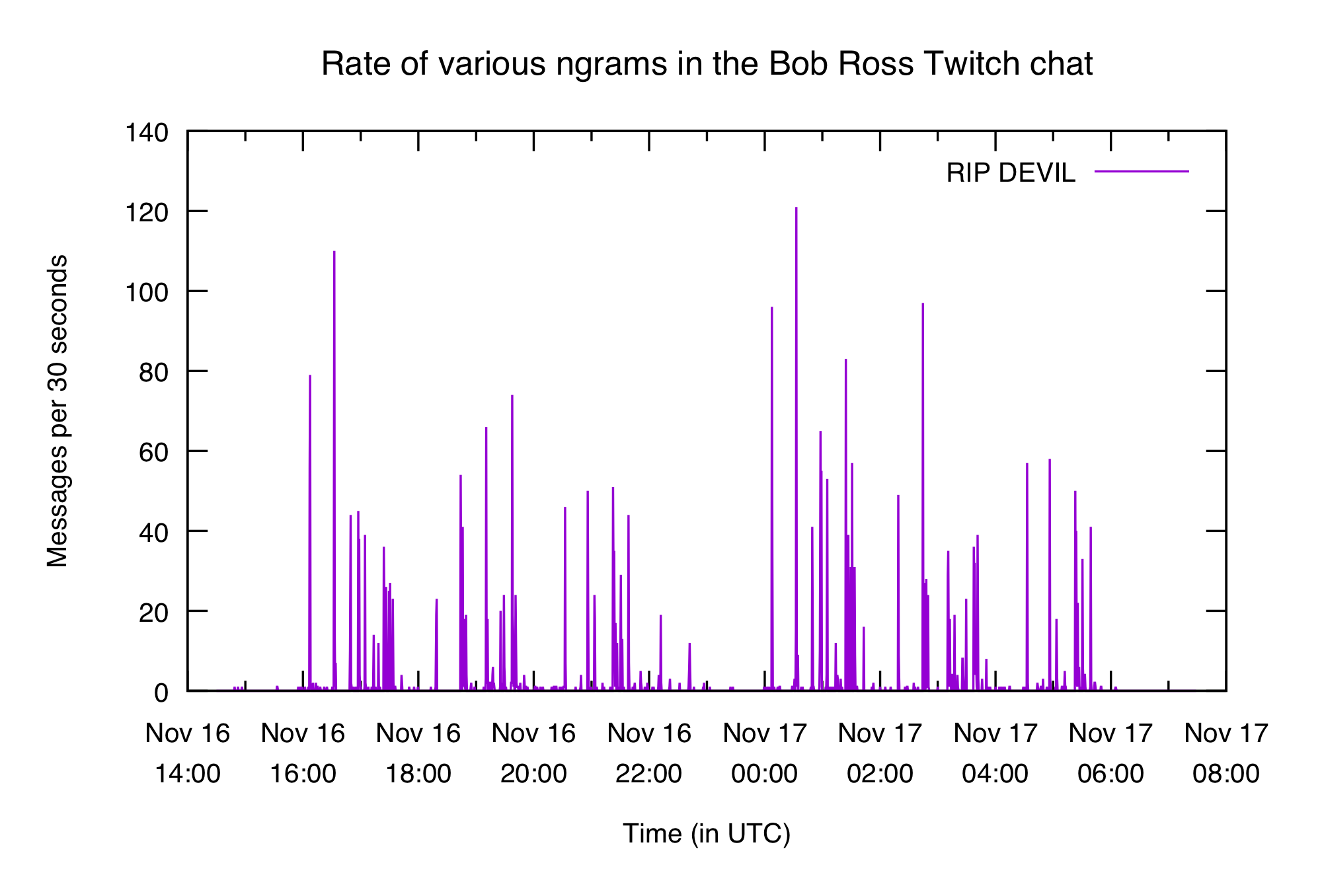
Looks like the devil isn't having a very good time. It's encouraging that the two seasons have roughly the same structure (three main clusters of peaks).
Note that there are a couple of smaller peaks between the two showings. Twitch showed another streamer painting between the two marathons, so it's likely that she cleaned her brush a couple of times and the chat responded. Fewer people were watching the stream during the break, hence the smaller peaks.
When did Bob get the most love? We'll use 5-minute x bins here because we just want a general idea.
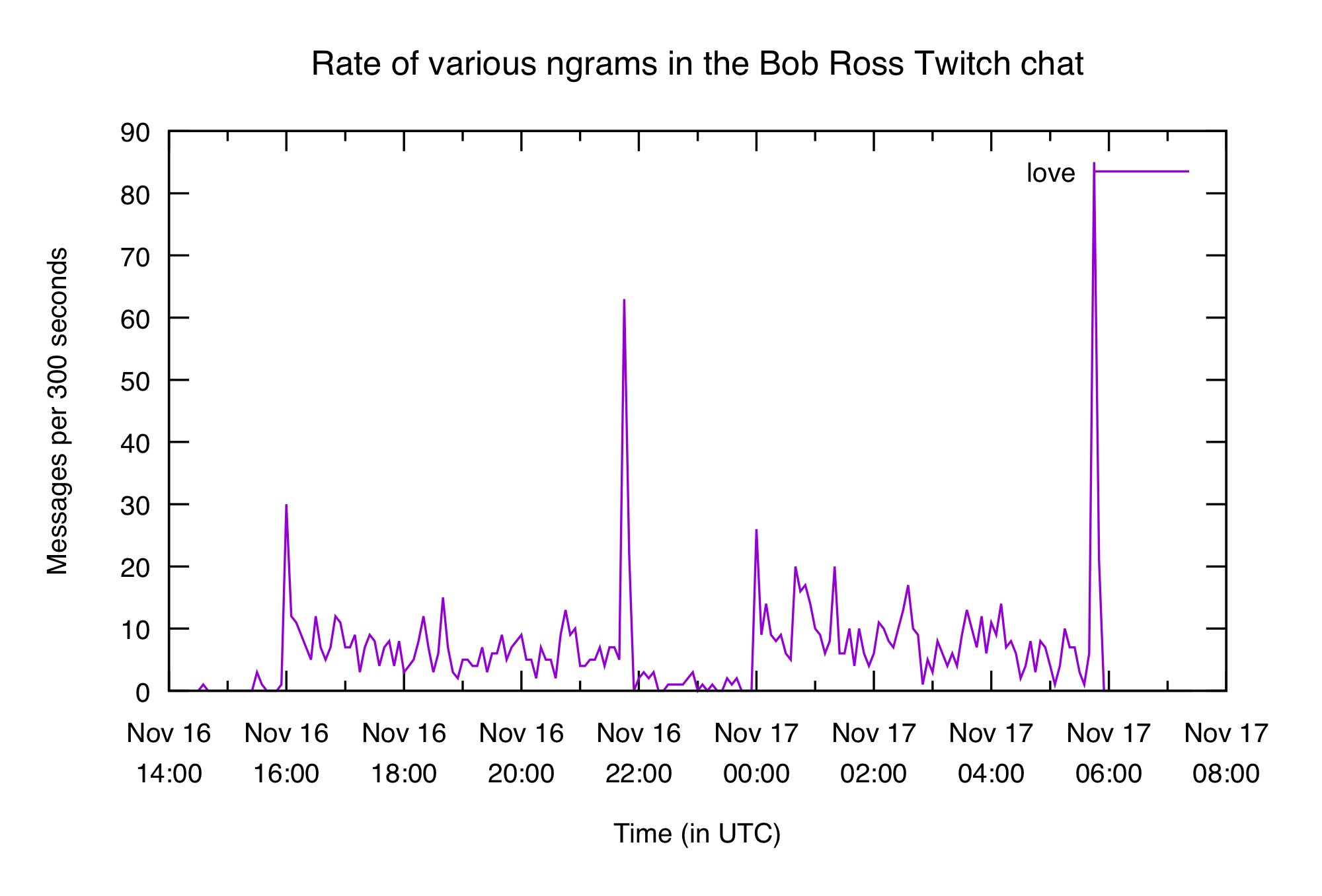
Lots of love all around, but especially as he signed off at the end.
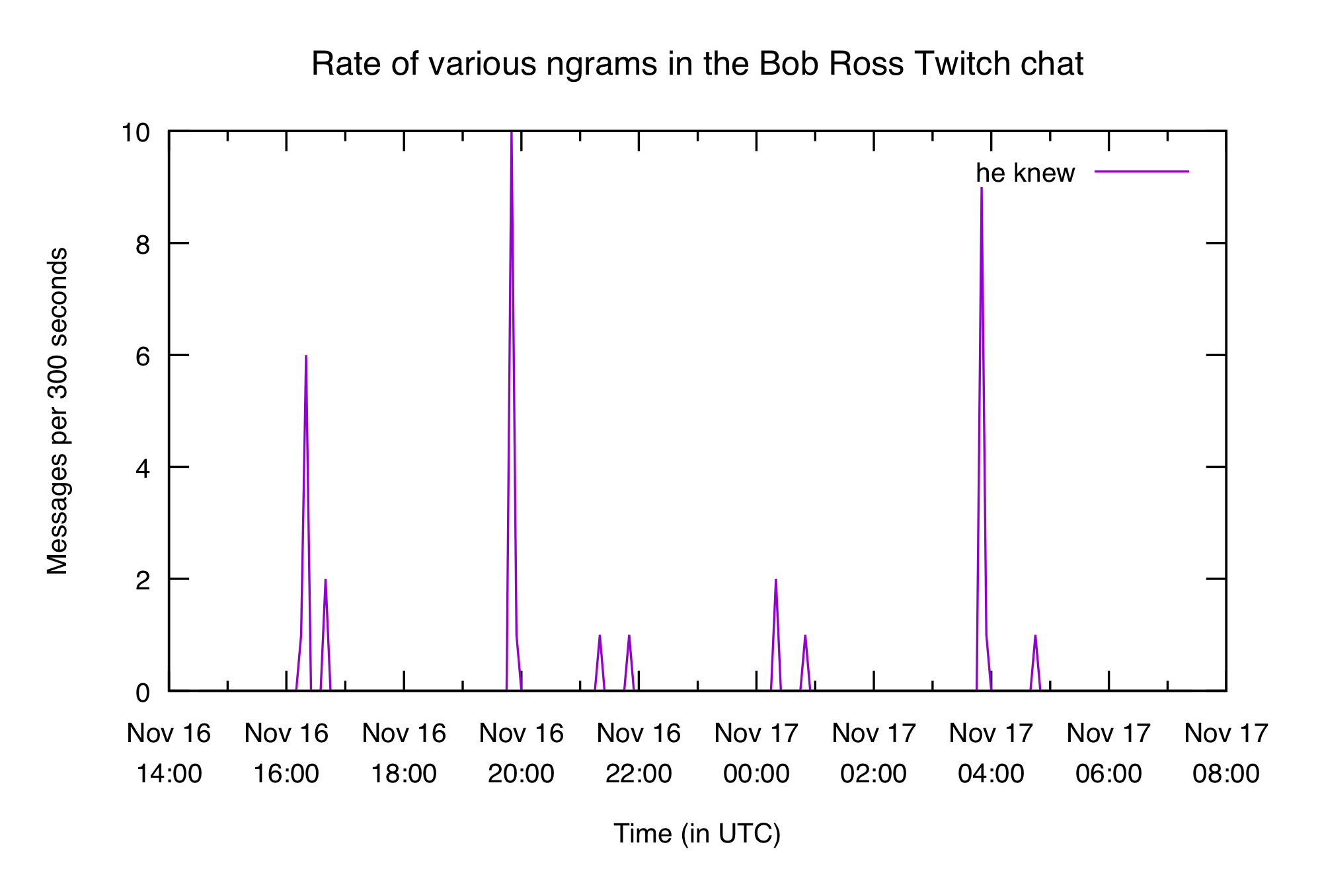
One of my favorite moments was when Bob said something about "changing your mind in mid stream" and the chat started spamming conspiracy theories about how he somehow knew about the stream 30 years in the past:
Up Next
Poking around at this chat corpus was a lot of fun (and definitely counts as studying for my NLP final, definitely). I'll probably record the chat during next week's marathon and do some more poking, specifically around finding unique events (e.g. his son Steve coming on the show) by comparing rate percentiles.
If you've got other ideas for things I should graph, let me know.